AWS Data Pipelineがついに利用可能になりました! こちらからサインアップすることができます!
最初のブログ記事でお話したように、AWS Data Pipelineを使えば、データ・ドリブンワークフローと、ビルトインの依存性チェック機能を使って、あらゆる量のデータの移動や処理を自動化することができます。AWS Data Pipelineはコマンドライン、API、AWS Management Consoleからアクセスすることができます。
今日はAWS Management Consoleを使って、独自のパイプライン定義を作成する方法を紹介いたします。まずはコンソールを開いて、サービスメニューからData Pipelineを選択するところから始めます。

Data Pipelineコンソールのメインページが表示されます。
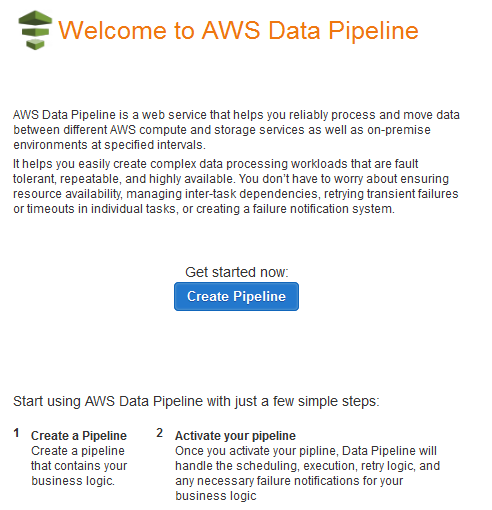
Create Pipelineをクリックし、フォームに入力します。
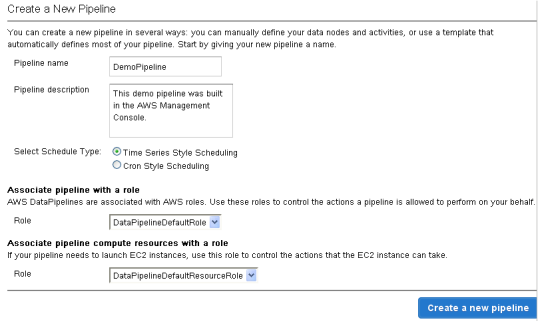
すると、実際のパイプラインエディタへアクセスできるようになります。
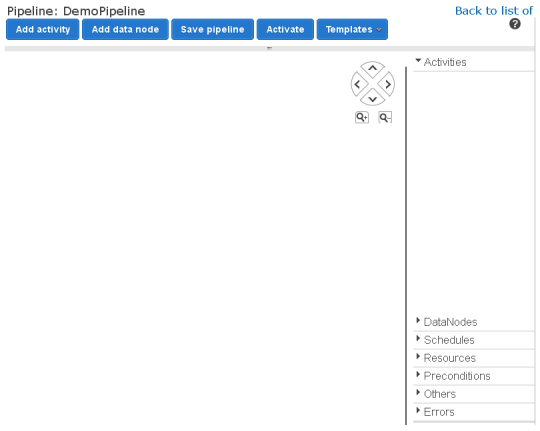
この時点で、2つのオプションがあります。完全にスクラッチからパイプラインを作る方法と事前に定義されたテンプレートのひとつを選択して始める方法です。
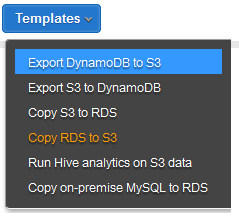
ここでは、最初のテンプレート、Export DynamoDB to S3を使うことにします。パイプラインは画面の左側に表示されます。
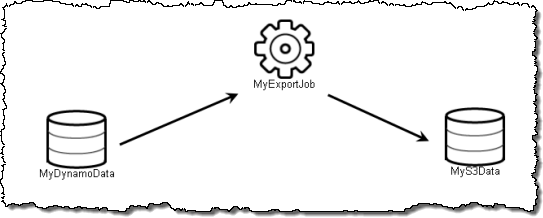
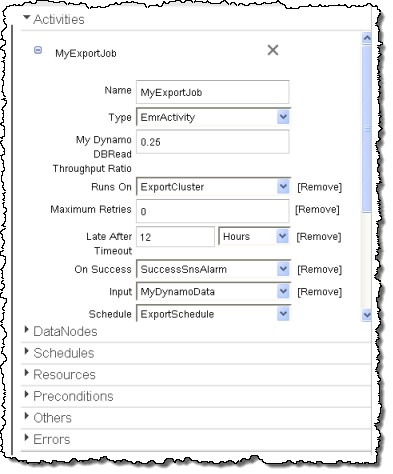
アイテムを選択しクリックすると、右側にその属性が表示されます。
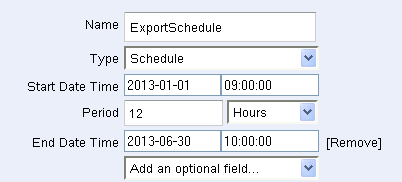
ExportSchedule (Scheduleタイプの項目)はどれくらいの頻度で、どれくらいの期間、パイプラインを実行するか指定します。 ここでは、12時間毎に、2013年の最初の6ヶ月間実行するよう指定しています。
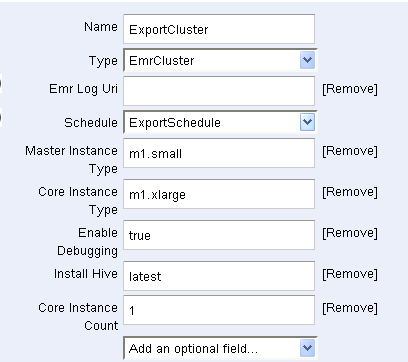
ExportCluster (Resource)はElastic MapReduceクラスターがデータを移動するのに使われることを指定します。
MyDynamoDataとMyS3Dataはデータソース(DynamoDBのテーブル)と宛先(S3バケット)を指定します。
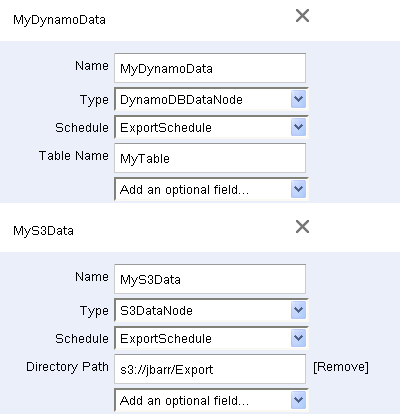
成功もしくは失敗の通知(表示はされません)はAmazon SNS トピックによって提供されます。

最後に、MyExportJob (Activity)がこれらすべてを一纏めにしています。
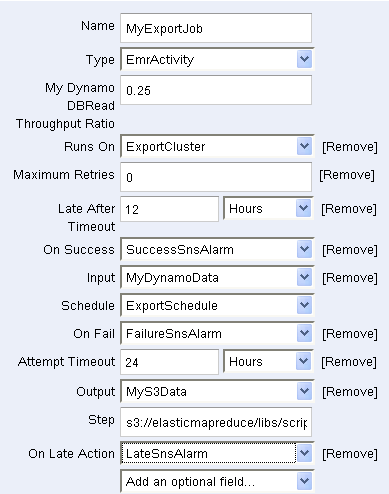
パイプラインの準備ができたら、それを保存して、アクティブにすることができます。

その他にAWS Data Pipelineを使いはじめるのに有用なリソースを紹介いたします。
- AWS Data Pipeline ホームページ
- AWS Data Pipeline Developer Guide
- AWS Data Pipeline API Reference
- AWS Data Pipeline FAQ
AWS Data Pipelineを是非お楽しみください! 皆様のフィードバックをお待ちしております!