この記事はAWSシニアエバンジェリスト Jeff BarrのAmazon Web Services Blogの記事、AWS Data Pipeline Now Supports Amazon Redshiftを平山毅 (Facebook, Twitter)が翻訳したものです。
AWS Data Pipeline (詳しい情報についてはブログの紹介記事をご覧ください。)は特定間隔でコンピュートとストレージのサービス間のデータを統合・処理するのに役立つWeb Serviceです。リソースや可用性、内部処理の依存性、一時的な失敗、タイムアウト、を心配することなく高い拡張性のある手法で クラウドやオンプレミスに蓄積されたデータを変換・処理することできます。
Amazon Redshift (詳しい情報はブログ記事をご覧ください。)は高速で、フルマネージドな数Gバイトからペタバイト以上までのデータセットに最適化されたペタバイト級でスケールするデータウェアハウスで、1年間のテラバイトあたりが$1000以下の費用しかかかりません。(従来のデータウェアハウスのおよそ1/10の費用です。) この記事からわかるように、最近、Redshiftの機能セットと利用可能なリージョンを拡張しました。
Data pipeline、Redshiftにこんにちは
本日は、この強力なAWS Servicesの組合せとして、Amazon Redhshiftが、AWS Data Pipelinte内で標準でサポートされ、接続可能になったことををお知らせします。
このサポートは、2つの新しい機能を使うことによって、実装されます。
RedshiftCopyActivityは Amazon DynamoDBやAmazon S3から新規か既存のRedshiftのテーブルにデータをバルクコピーするのに使用されます。 さまざまな方法で、この強力な機能を利用できます。 もし、関係性のあるデータが蓄積されたAmazon RDSや Hadoopスタイルな並列処理を行うためAmazon Elastic MapReduceを使っているならば、 Redshiftにそのデータをロードする前にS3にデータを配置させて実現することできます。
SqlActivityは、Redshiftに蓄積されたデータに対してSQLクエリを実行するために使用されます。 実行されるクエリに加えて、入力用と出力用のテーブルをそれぞれ指定できます。 出力用に新規のテーブルを作成することもでき、既存のテーブルにクエリー結果をマージさせることも可能です。
これらの新規Activityは、AWS Management Console内のグラフィカルなパイプラインエディター、新しい「Redshift Copy template」、AWS CLI、AWS Data Pipeline APIsを使ってアクセスできます。
一緒にデータ配置する
代表的な使用例を見ていきましょう。
ECのWebサイトを運営していて、15分単位でWEBサイトのアクセスログをAmazon S3にデータ挿入すると仮定します。
毎分、ログを整えるためにHiveを使い、SQLデータベースに関連する顧客データと結合し、
Redshiftにデータをロードし、地域ごとの売上や日次の顧客セグメントのような統計情報を
計算させるため、SQLクエリーを実行します。
最後に、長期分析のため、Redshiftに日次のデータを蓄積します。
AWS Management Consoleを使ってこのような処理を行うパイプラインの定義方法は以下の通りです。
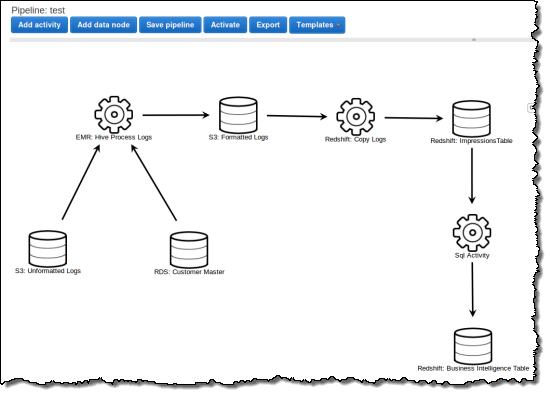
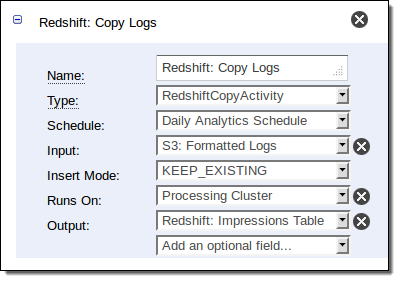
表示されたパイプラインでS3からRedshiftにデータをコピーするActivityの定義方法は以下の通りです。
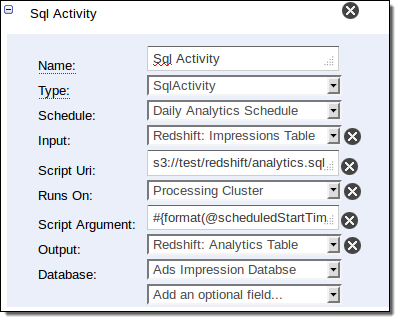
そして、統計処理方法は以下の通りです。
さあ、今すぐ始めましょう。
AWS Data Pipeline は米国東部(北バージニア)リージョンで利用でき、このリージョンのRedhiftへのアクセスをサポートします。現在、ElasticMapReduceおよび、DynamoDBはクロスリージョンのワークフローをサポートしておりますが、将来、Redshiftへのクロスリージョンのアクセスをできるようにする予定です。
Copy to Redshiftのドキュメントからまずはスタートしてみてください!
-- Jeff;
この記事はAWSシニアエバンジェリスト Jeff BarrのAmazon Web Services Blogの記事、AWS Data Pipeline Now Supports Amazon Redshiftを平山毅 (Facebook, Twitter)が翻訳したものです。