Amazon DynamoDBに対する最も良くいただく機能リクエストのうちの2つは、バックアップ/リストアとリージョンを超えたデータ転送です。
 本日、DynamoDBのテーブルとAmazon S3のバケット間をデータ転送するのに使用できる2つのスケーラブルなツール(インポートとエクスポート)を導入することにより、これらのリクエストの両方に対応いたしました。 エクスポートおよびインポートのツールは、データ転送プロセスをスケジュールし、管理するのにAWS Data Pipelineを使用しています。実際のデータ転送はインポートまたはエクスポートのオペレーションの一部として起動、管理、停止されるElastic MapReduceのクラスター上で実行されます。
本日、DynamoDBのテーブルとAmazon S3のバケット間をデータ転送するのに使用できる2つのスケーラブルなツール(インポートとエクスポート)を導入することにより、これらのリクエストの両方に対応いたしました。 エクスポートおよびインポートのツールは、データ転送プロセスをスケジュールし、管理するのにAWS Data Pipelineを使用しています。実際のデータ転送はインポートまたはエクスポートのオペレーションの一部として起動、管理、停止されるElastic MapReduceのクラスター上で実行されます。
言い換えれば、エクスポート(ワンショットか毎日のいずれかを選択できます)またはインポート(ワンショット)の操作を設定しさえすれば、AWS Data PipelineとElastic MapReduceのコンビが後の面倒を見てくれます。 電子メールアドレスを設定して、各処理のステータスを通知するために使用することもできます。
ソースバケット(インポート用)と宛先バケット(エクスポート用)はどのAWSリージョンのものでも指定できるので、この機能をデータのマイグレーションやディザスタリカバリ用に使用することもできます。
エクスポートおよびインポートツアー
エクスポートおよびインポートのクイックツアーを見てみましょう。両方ともAWSマネージメントコンソールのDynamoDBタブからアクセスすることができます。Export/Importボタンをクリックすることによりスタートします。:
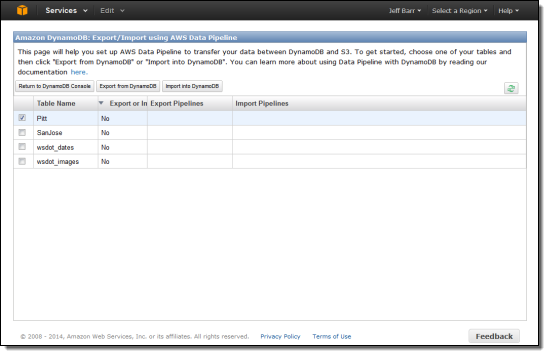
この時点で、2つのオプションがあります。複数のテーブルを選択し、Export from DynamoDBをクリックするか、一つのテーブルを選択し、Import into DynamoDBをクリックすることができます。
Export from DynamoDBをクリックした場合、データおよびログファイル用に希望のS3バケットを指定できます。
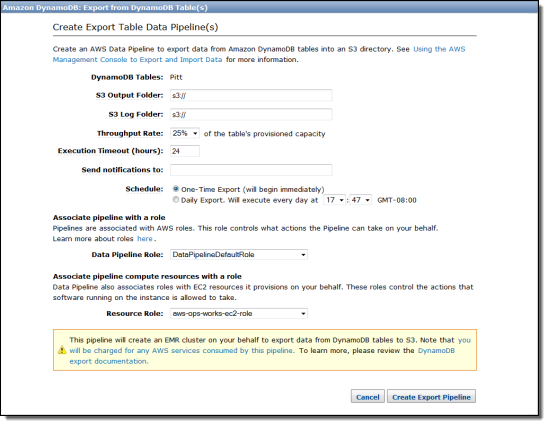
ご覧のように、エクスポートのプロセスにテーブルのプロビジョンドスループットをどれだけ割り当てるか(5%刻みで10%から100%)を決めることができます。 すぐに一回だけのエクスポートを実行するか、指定の時間に毎日実行するかを選択することができます。 また、パイプラインとコンピュートリソースを代わりにプロビジョンするために使用するIAM roleを選択することもできます。
ここでは所有するテーブルのひとつをすぐにエクスポートすることを選択し、開始されたMapReduceのジョブを見ています:
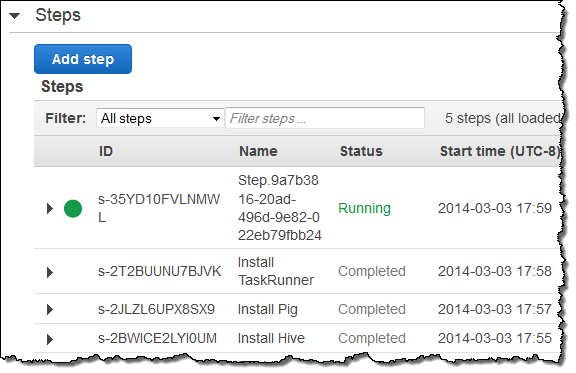
エクスポート操作は数分以内に終了し、データがS3内に作成されていました:
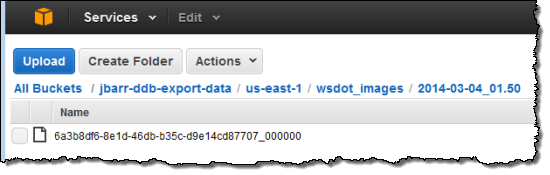
ファイルのキーには日付と時間、ユニークなIDが含まれていますので、毎日実行されるエクスポートはS3に蓄積されていきます。 蓄積されたデータの制御に、S3のライフサイクル管理機能を利用することができます。
ファイルをダウンロードし、DynamoDBのレコードが含まれているか確認してみました。:
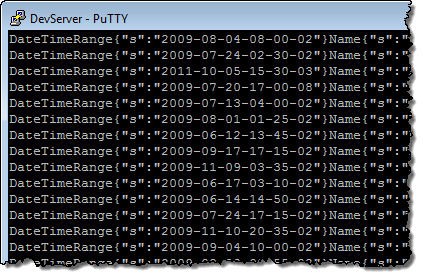
このスクリーンショットでは見ることができませんが、属性の名前はSTXおよびETX ASCII文字をサポートしています。ファイルのフォーマットに関するさらに詳しい情報についてはVerify Data File Exportのセクションをご参照ください。
インポートプロセスも同じように簡単です。1度に1つのテーブルを、必要な数だけワンショットインポートジョブを作成することができます。:
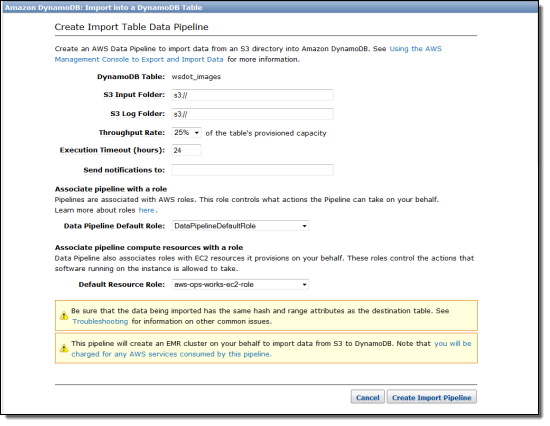
繰り返しになりますが、S3はここで重要な役割を果たしており、インポートプロセスにどれだけのスループットを割り当てるか制御することができます。 インポートを設定する際、入力データ用の特定の「フォルダ」を指定する必要があります。 この機能のもっとも一般的なユースケースは以前にエクスポートされたデータのインポートですが、既存のリレーショナルデータベースやNoSQLデータベースからデータをエクスポートし、こちらにあるような構造のデータに変換し、生成されたファイルをDynamoDBにインポートすることもできます。
-- Jeff;
この記事はAWSシニアエバンジェリスト Jeff BarrのAmazon Web Services Blogの記事、 Cross-Region Export and Import of DynamoDB Tablesを 堀内康弘 (Facebook, Twitter)が翻訳したものです。