同僚の Tina Adams がAmazon Redshiftのクールでパワフルな新機能をゲスト投稿してくれたので紹介します
— Jeff;
Amazon Redshift, このフルマネージドのデータウェアハウスサービスは高速にかつ簡単に多様なデータの解析を可能にします。160GBのクラスターを2ヶ月無料で試用することができ、数ペタバイトクラスまで$1,000/TB/年以下の費用でスケールさせることが可能です。Amazon Redshift はMPP(massively parallel processing)のスケールアウト可能なアーキテクチャを使用しており 、データサイズの大きさに応じてコンピュート(演算)リソースが増加します。また、ダイレクトに接続されたストレージにカラム指向(カラムナ)でデータを配置することで、大幅にI/O時間を削減します。 多くのお客様( Pinterest, Euclid, Accordant Media, Asana, Coursera 等)はAmazon Redshiftによって、大幅な処理速度向上を達成されています。
I/Oを削減することは、データウェアハウスのクエリーパフォーマンスにとって大変重要です。Amazon RedshiftでI/Oパフォーマンスを増加させる1つの方法としては、Sort Key(ソートキー)を表に定義し、スキャン対象の範囲を小さくすることが可能です。Sort keyを指定するとAmazon Redshift内でゾーンマップが作成され(メモリ上に保存)、1MB単位で管理されたデータブロックの中から不要なブロックのスキャンをスキップすることが可能です。例えば5年間分のデータを保持している表が日付の列でSort key定義されている場合、ある単月のデータをクエリーした際に、98%のブロックを読み飛ばすことが可能になります。
しかし、Sort keyの定義に無い列で結果をフィルターしたい(絞り込みたい)場合はどうすれば良いのでしょうか?行指向の一般的なデータベースでは、セカンダリーのインデックスを作成して、プライマリーキー列以外でのフィルターに対し、アクセス範囲を削減することが可能です。インデックスはカラム指向でブロックサイズが大きいRDBではあまり選択の絞り込みに効果がありません。代わりにカラム指向のシステムではしばしば表から対象列全体をコピー、ソートして、表とは別に管理をするという手法が取られます。これをプロジェクションと呼びます。しかし、インデックスにしてもプロジェクションにしても、その処理には大きなオーバーヘッドがかかってしまいます。ロードしたデータだけでなく、インデックスやプロジェクションの分まで追加の管理が必要になります。例えば3つのプロジェクションを定義すると、データのロード時間が2-3倍になります。しかも、列の数が多くなると、プロジェクションの対象となる列の組み合わせも指数関数的に増加します。8つ列がある場合では、最大40,000個のプロジェクション対象の組み合わせが考えられるのです。
新機能:Interleaved Sort Key
プロジェクションやインデックス無しで、クエリーのフィルターを高速に行うために、Amazon RedshiftはInterleaved Sort Key機能が追加されました。この機能は今後7日間かけて全リージョンにデプロイされる予定です。Interleaved sort keyは、ユーザが指定した複数のソート対象の列を、それぞれ同等に扱うようにアレンジします。Interleaved sort keyは、複数の列でフィルターしながら、高い絞り込み度合いでセレクトする必要がある場合に最も大きな効果を発揮します。
(※訳注:ブロク記載時点では日本語マニュアルにはまだInterleaved Sortの記載がありませんでした。リンク先のドキュメントでInterleaved Sortについての記述が見当たらない場合は、英語に切り替えてご覧ください)
例として100,000個の1MBブロックで構成された表があり、1つ、もしくは4つの列(date, customer, product, geography)でフィルターをする処理をしばしば実施するとしましょう。このような環境でこれまでのRedshiftで利用できるcompound sort key(複合ソートキー)を作成することで対応する場合、最初にdate列でソートした後に、customer, product,そして最後にgeographyの順でソートされてデータが保管されます。この場合実行するクエリーのフィルター条件がdateであった場合はうまく動くでしょう。しかし、geographic列のみのフィルタ条件では、100,000ブロックの全体スキャンが実行されてしまいます。Interleaved sortは、どのキー列をWHERE句に指定するかにかかわらず高速なフィルター処理を提供します。あなたが4つのキーのうち、1つのキーのみフィルター条件に指定した場合、5,600ブロック、すなわち100,000(3/4)ブロックのみのスキャンで済みます。もし2つの列を検索条件にした場合はさらに減少して316ブロック、つまり100,000(2/4)ブロックのみのスキャンで処理が完了します。そして4つのソートキー全てを条件に指定した場合は、たった1つのブロックのみで良いのです。
マジックのようでしょうか?いえ、これは純粋な数学なのです。別の例で考えてみましょう。Webサイトを運営しているとして、アクセスが多いWebページとカスタマーを分析したいとします。データベース上は2つのSort key (cust_idとpage_id)があり、合計4ブロックに配置されているとします。どのようにすれば、WEBページとお客様の分析を高速に行えるでしょうか?compound sort keyを使う場合、最初にcust_idでソートされ、その後にpage_idでソートされてデータが格納されます。([1, 1]という表記は、cust_idが1で、page_idが1である事を表しています):

これは、「同じカスタマーに閲覧されたページが、同一のブロック(上図のオレンジ色の枠)に収まる」ということです。もしある特定のカスタマーの閲覧ページを得る場合はたったの1ブロックのスキャンで済みますが、特定のページに訪れたカスタマーを得る場合は、4つのブロック全てをスキャンする必要があります。
ではinterleaved sortの場合はどうでしょうか。Interleaved sortを利用した場合はカスタマー(cust_id)とWebページ(page_id)が同等に扱われるように配置がアレンジされます:
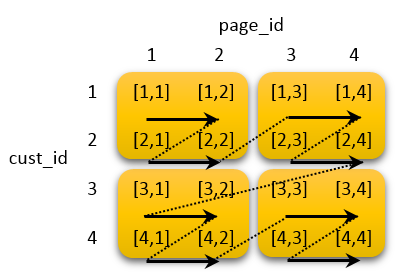
このように、最初の2つのcust_idは最初のブロックに格納され、最初の2つのpage_idとの組み合わせで同じブロックに格納されます(ソートの順は指定可能です)。これによって、カスタマー単体での検索でも、ページ単体での検索でも同じく2ブロックのスキャンで処理が完了します。
Interleaved sortを使うことによるパフォーマンス上のメリットがどの程度あるかはテーブルのサイズに依存します。もしテーブルが1,000,000ブロック(1TB)で構成されており、そこでcust_idとpage_idを指定した場合、特定のcust_idもしくはpage_idに対するスキャンは1,000ブロックで済みます。これはソートされていないケースと比較して1000倍の速度アップになります。
Interleaved sortを指定するには、以下のようにCREATE TABLEでSORT KEYの前にINTERLEAVEDと指定するだけです。最大で8つまでのsort key列を指定できます。
CREATE TABLE PageViews (customerID INTEGER, pageURL VARCHAR(300), duration INTEGER)
INTERLEAVED SORTKEY (pageURL, customerID);45,000,000行あるデータを上記に表に挿入してinterleaved sort keyを設定してみたところ、ソートされた列のサブセットを取得するクエリーがcompound sort keyを使った場合と比較して平均12倍高速になました。以下のようなクエリーです。
SELECT COUNT(DISTINCT pageURL) FROM PageViews WHERE customerID = 57285;
Run time...
Compound Sort: 21.7 sec
Interleaved Sort: 1.7 sec
Interleaved Sortはキーが1つの列である場合も同様に有効です。ゾーンマップはsort keyに指定された列の値の最初の8バイトを格納しています。pageURLという列にcompound sort keyを指定した場合、最初の8バイトは“http://w”であり、これは列の選択を絞る効果が低いと言えます。しかしInterleaved sortでは列の値が圧縮されることで、264種類ものURLをゾーンマップに格納できるようになります。
一方で、compound sort ketとinterleaved sort keyの間にはトレードオフがあります。もしクエリー対象の列がいつも同じであれば、compound sort keyを使う方が適しているでしょう。上のSQLの例で言うと、フィルターにcompound sort keyの最初の列であるpageURLを指定した場合は、compound sort keyを使った場合の方がinterleaved sort keyに対して0.4秒高速に実行できました。これはCompound sort keyが最初に指定した列を優遇した配置であることから考えると意外な結果ではないでしょう。データセットの内容にもよりますが、interleaved sort keyを使用した場合の方が、compound sort keyと比べてvacuumの時間が10-50%増加します。データセットが単調に増加するようなケース、例えば日付等においては、interleaved sortの並び順が時間経過によって少しずつ劣化していくため、vacuumを実行して、データの配置を再計算させ、ソートしなおすことが重要です。
Interleaved sort機能は、これから7日間かけて全リージョンに展開されます。クラスターのバージョンは1.0.921に更新される予定です。
さらに学習するには
チュートリアルのOptimizing for Star Schemas with Amazon Redshiftでは上記のようなトレードオフをより詳細に解説しています。APNビジネス・インテリジェンスパートナーであるLookerは、interleaved sortのパフォーマンスメリットについて、すばらしいブログポストを掲載しています。sort key定義方法についてのより詳細な情報は、 Best Practices for Designing Tablesを参照してください。また、redshift-feedback@amazon.com宛へのフィードバックもお待ちしております。
引き続きご注目を
Amazon Redshiftには、これからも新しい機能が追加予定です。ぜひご注目ください。最新機能のアナウンスを得るには、Amazon Redshift Forumにログインしていただき、Amazon Redshift Announcementsスレッドを購読してください。Developer Guideの更新履歴やManagement Guideの更新履歴を確認いただくことでも情報を得ることができます。
— Tina Adams, シニアプロダクトマネージャー (翻訳:下佐粉 昭)