Amazon EMR上でApache Sparkがサポートされました!そのことについてEMRのプロダクトマネージャのJoh Fritzのブログを書いていますので、これを翻訳してみます。
元記事はこちら: New – Apache Spark on Amazon EMR
今井
--
本日、Amazon EMRはApache Sparkをサポートしたことを発表いたします。Amazon EMRはHiveやPig、HBase、Presto、ImpalaなどのHadoopエコシステムによって、大量のデータを処理することを容易にしてくれる、AWSのサービスのひとつです。また、これまでもBootstrapアクションや自前のスクリプト等を利用してEMRにSparkをインストールしてご利用頂いているお客様もたくさんいらっしゃいました。しかし今日からは、マネジメントコンソールやAPI、CLIで’Sparkをインストールする’というオプションを指定するだけでSparkを利用することができます!
Apache Spark: Beyond Hadoop MapReduce
これまで、非常に多くのお客様がHadoop MapReduceを使って大量のデータをバッチ処理したり、構造化されていないデータに対してアドホックな分析を行ったり機械学習を走らせたりしてきました。Hadoopエコシステムの新しいメンバーであるApache Sparkは、これらのワークロードのうちおおくのものをより高速に処理することができます。
Apache Sparkは有向無閉路グラフ(たぶん、DAGと言ったほうがわかりやすいですね)実行エンジンを利用することによって、非常に効率的なデータ処理の実行プランを作成します。また、Sparkは取り扱うデータをRDD(Resilient Distributed Datasets)と呼ばれる、インメモリであり耐久性の高い、イミュータブルなデータセットの形に抽象化して利用します。この2つの特徴により、Hadoop MapReduceのmap-reduceフレームワークの課題であったIOコストを極小化し、高いパフォーマンスを実現してくれます。この特徴は同じデータを何度も再帰的に処理する、機械学習のようなワークロードにとって非常に大きなメリットをもたらします。
また、SparkはないティブでScala、Python、JavaのAPIを持っており、それぞれのAPIに対してSQL、機械学習、グラフ処理、ストリーム処理のライブラリが用意されています。Spark自体がこのような開発者向けの多様なオプションを用意していますので、Hadoop MapReduceよりもかなり開発がし易いのは間違いないと思います。
Apache SparkとAmazon EMR
ここまではSparkについての紹介をしてきました。本日より、マネジメントコンソール、API、CLIなど様々な手段で簡単にSparkがインストールされたEMRのクラスタを構築することができます。もちろん、SparkとともにこれまでどおりEMRの特徴であるAmazon EMR FS(EMRFS)を使ってAmazon Simple Storage Service(S3)上のデータを取り扱ったり、処理のログをS3に吐き出したり、EC2 Spot Instanceを利用することができるのは言うまでもありません。そして非常に重要なことですが、Sparkを利用するにあたって追加費用は要りません。
Sparkには高速なデータクエリエンジンであるSpark SQL、機械学習アルゴリズムのライブラリであるMLlib、分散環境上でのストリーム処理を実現するためのSpark Streaming、グラフ処理のためのGraph Xが含まれています。また、併せてGangliaをインストールすることによってSparkの各種メトリクスを監視することもできます。そしてEMRの大きな特徴のひとつでもある、EMR Step APIを使ってSparkのジョブをサブミットすることもできます。もちろん、マスタノードにSSHでログインしてSpark Shellを起動することもできますし、Spark APIを直接利用することもできます。
Spark on EMRの事例
次はAmazon EMR上でのSparkのユースケースをいくつかご紹介したいと思います。
Washington Postは記事やコンテンツのレコメンドにSparkを利用しています。
Yelpはディスプレイ広告のクリック率をあげるためにMLlibを使っています。
Hearst Coporationはクリックストリームのリアルタイム処理のためにSpark Steramingを利用しています。これにより、記事ごとの効果をリアルタイムにモニタリングを実現しています。
Kruxは自社のサービスであるDMPのためにSparkを使ってAmazon S3(EMRFS経由で)上のデータを処理しています。
Sparkを使った分析処理の簡単なサンプル
では、Spark on EMRでデータ分析をする簡単なサンプルを見て行きましょう。
今回は米国運輸省が公開しているパブリックデータセットであるpublic data set outlining flight information since 1987. を使います。これをダウンロードしてカラムナ型のParquet formatに変換し、S3上にアップロードしました(リードオンリーで皆様も利用可能です!)。このデータは4GB(非圧縮だと79GB)のサイズがあり、行数にすると162,212,419行ありますので、分散処理フレームワークの性能を試すにはそれなりによいデータ量であるといえるでしょう。
ここでは出発便の多い空港TOP10を知りたいとします。このクエリをSQLに書き落とし、Scalaで下記のようなSparkアプリケーションを書き起こします。このコードは下記からダウンロードすることも出来ます。 s3://us-east-1.elasticmapreduce.samples/flightdata/sparkapp/FlightExample.scala
コード中で"flights"というテーブルを作っていることに注目してださい。これはRDDとして保存されます。SQLはこのRDDに対して実行されることになりますが、RDDはメモリ上に展開されるデータセットですのでIOコストを非常に小さく抑えることができます。また、EMR上のSparkはEMRFSを経由してS3上のデータを直接取り扱うことができますのでHDFS上にデータをコピーしておく必要もありません。もちろん、このコードサンプルにあるように出力先もS3を指定することができあす。それでは実行するためにこのコードをJARにビルドします。ビルド済みのJARはこちらからダウンロードできます。https://s3.amazonaws.com/us-east-1.elasticmapreduce.samples/flightdata/sparkapp/flightsample_2.10-1.3.jar
それでは3ノードのm3.xlargeからなるAmazon EMRのクラスタを起動しましょう。このサンプルデータセットはUS EastのS3上に配置されているので、クラスタも同じリージョンに起動してください。もちろん別リージョンでも動きますが。マネジメントコンソールにアクセスし、以下のように起動していきます。
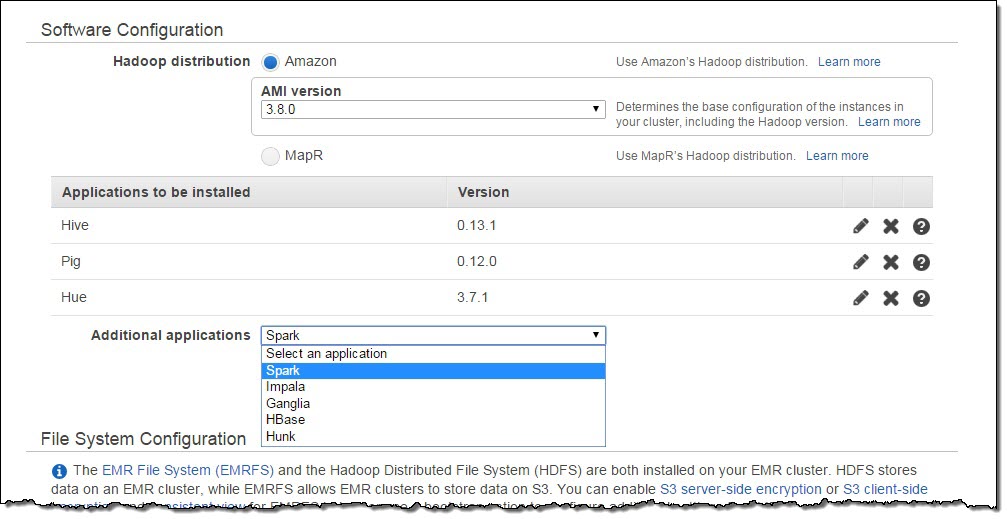
Additional Applicaitonのところまで画面をスクロールしていき、ドロップダウンリストからSparkを選択してください。Arguments(引数)には、下記のように-xと入力してください。 このパラメータは、例えばSparkのデフォルトのexecutorの数を上書きするときなどに利用します。
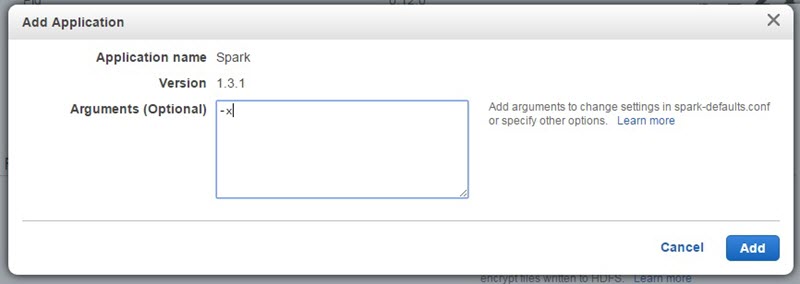
EMRのAMI3.8.0にインストールされるSparkの各種設定はApacheプロジェクトのデフォルト値をそのまま使っており、RAM1GBあたり2executorということになります。-xを渡してやると、executor数をクラスタ作成時のEMRのコアノードの数に上書きし、各executorに割り当てられるRAMとvcoreの数を、各コアノードがサポートする最大値で設定してくれます。当然この設定に寄ってジョブのパフォーマンスが変わってきますので、いろいろな設定を試すことをおすすめします。もちろんspark-submitを実行するときにこれらの値は更に上書き可能です。
更に Stepsセクションまで画面をスクロールしていき、下記のように2つのステップを追加しましょう。最初のステップはビルドされたアプリケーションのJARをS3からマスタノードにコピーするためのものです。 Custom jarステップとしてScriptRunnerという、任意のシェルスクリプトを実行するためのJarを利用します。Jarのロケーションは s3://elasticmapreduce/libs/script-runner/script-runner.jarを指定してください。そして引数として、実際に実行させたいコマンドである /home/hadoop/bin/hdfs dfs -get s3://us-east-1.elasticmapreduce.samples/flightdata/sparkapp/flightsample_2.10-1.3.jar /mnt/を渡してあげてください。画面的には下記のようなイメージです。
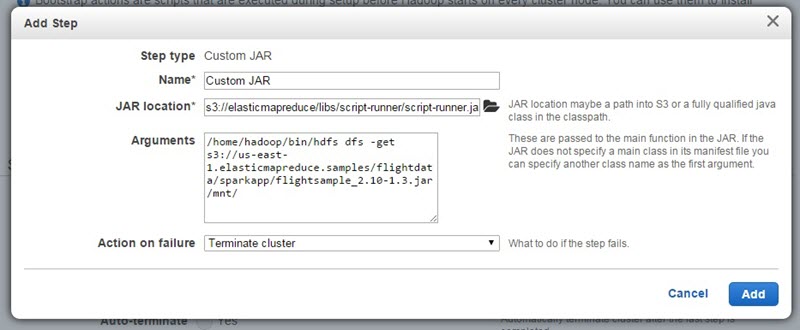
2つめのステップではSparkアプリケーションを実行させます。
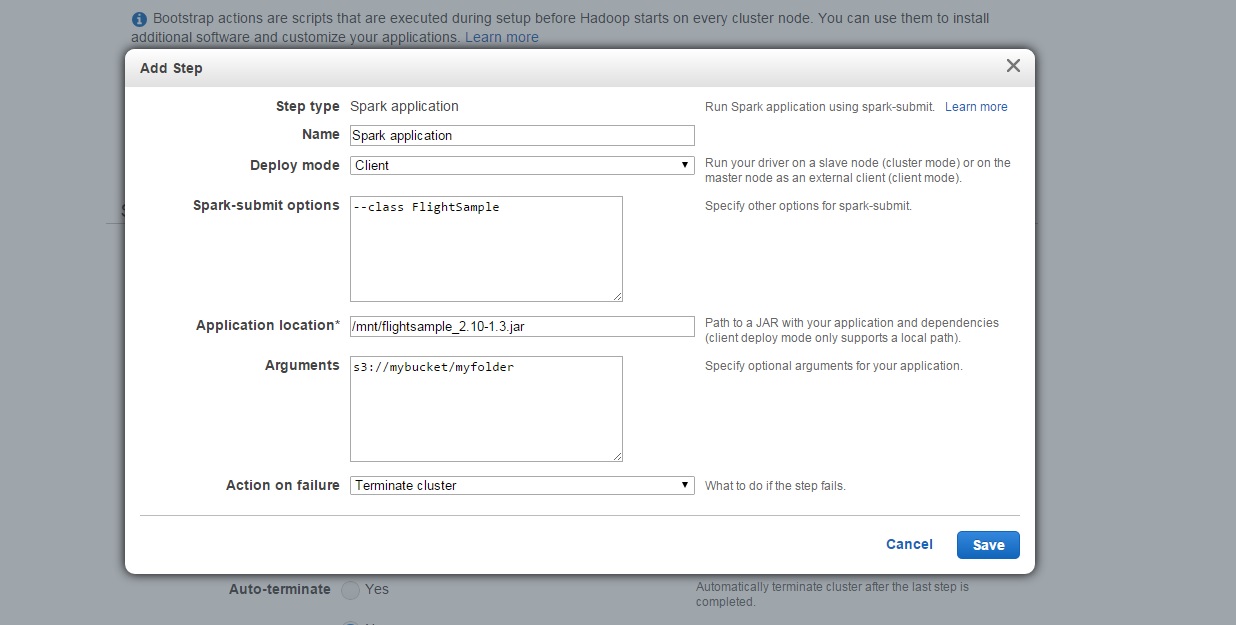
Deploy Modeには Clientを指定してください。また、 Application locationにはJarのローカルパスを指定してやる必要があるので、先のステップでダウンロードしたパスである/mnt/flightsample_2.10-1.3.jarを指定してください。アプリケーションへのArguments(引数)には出力先として任意のS3バケットのパスを指定してください。そして Action on failureに Terminate clusterを指定します。
最後に Auto-terminateをYesに設定します。これにより、アプリケーションが終了すると自動的にこのクラスタは終了されることになります。さて、もろもろ準備が整ったので Create Clusterをクリックしましょう!
Amazon EMRがクラスタを起動し、Sparkアプリケーションを実行し、ジョブが終了し次第クラスタを廃棄してくれます。この様子はマネジメントコンソールの Cluster Detailsにて観察することができます。そしてジョブが無事に終了していれば、指定したS3バケットにアプリケーションの結果である、出発便の多い空港TOP10が出力されていることでしょう。
Spark on EMRは今日から利用可能です!
Spark on EMRについてより詳細な情報を知りたい方はSpark on Amazon EMRをご確認ください!