Amazon DynamoDBのテーブル毎にローカルセカンダリインデックスを作成することができるようになりました。ローカルセカンダリインデックスを使えば新しい方法でテーブルを照会することができ、検索効率を向上させることができます。
ローカルセカンダリインデックスとは?
ローカルセカンダリインデックスモデルはDynamoDBの既存のキーモデルの上に構築します。
本日までは、テーブルを作成する際、次の2つの主キーオプションのいずれかを選択する必要がありました。
- ハッシュ - 特定のテーブル内の各アイテムを一意に識別する、厳密に型指定(文字列、数字、バイナリのいずれか)された値
- ハッシュ + レンジ - 2つの組み合わせて、特定のテーブル内の各アイテムを一意に特定する値を形成する、厳密に型指定された項目のペア。DynamoDBは主キーのハッシュ部分に一致するアイテムの一部もしくは全てを取得できる、レンジクエリーをサポートする。
本日のリリースで、ハッシュ + レンジオプションを、テーブル毎に最大5つのローカルセカンダリインデッスサポートするよう拡張しています。主キーのように、ローカルセカンダリインデックスもテーブル作成時に定義する必要があります。各インデックスは主でない属性を参照し、ハッシュキーと特定の2つ目のキーを組みあわせた検索を効率的にしてくれます。
また、セカンダリインデックスにテーブルの他の属性の一部もしくは全てを投影するかどうかを選択できます。DynamoDBは必要に応じて、テーブルもしくはインデックスから属性の値を自動的に取得します。特定の属性を投影することで、取得スピードを改善したり、消費されるプロビジョンドスループットの量を減らすことが期待できますが、追加のストレージスペースが必要になります。セカンダリインデックス内の項目は、お互い物理的に近い場所に、クエリの性能を高めるためにソートされ、格納されています。
どのように使うのか?
米国の社長についての情報(非常に大きなデータセットだと考えてください。)を格納したテーブルアクセスする必要があるとします。
そして、 Find the Dataのデータを使って、ハッシュキーとしてNumber、レンジキーとしてDateTookOfficeを持つテーブルを作成します。
| Number | DateTookOffice | Name | VP | Party | Age | YearsInOffice |
| 1 | 1789-04-30 | George Washington | John Adams | None | 57 | 6.34 |
| 2 | 1797-03-04 | John Adams | Thomas Jefferson | Federalist | 61 | 4 |
| 3 | 1801-03-04 | Thomas Jefferson | Aaron Burr | Democratic- Republican | 57 | 8 |
| 4 | 1809-03-04 | James Madison | George Clinton | Democratic- Republican | 57 | 8 |
| 5 | 1817-03-04 | James Monroe | Daniel Tompkins | Democratic- Republican | 58 | 8 |
このスキーマでは、Number(番号)とDateTookOffice(日付)の範囲を使って、社長を検索することができます。ここで、さらにAge (就任時)によって照会したいとしましょう。この場合、次のようなローカルセカンダリインデックス(Age)を持ったテーブルを作成します。
| Number | DateTookOffice | Age |
| 1 | 1789-04-30 | 57 |
| 2 | 1797-03-04 | 61 |
| 3 | 1801-03-04 | 57 |
| 4 | 1809-03-04 | 57 |
| 5 | 1817-03-04 | 58 |
さらに、クエリの一部としてNameフィールドを取得することが多いと仮定します。この場合、より効率的にするために、Age属性をAgeNameインデックスに投影することができます。
| Number | DateTookOffice | Name | Age |
| 1 | 1789-04-30 | George Washington | 57 |
| 2 | 1797-03-04 | John Adams | 61 |
| 3 | 1801-03-04 | Thomas Jefferson | 57 |
| 4 | 1809-03-04 | James Madison | 57 |
| 5 | 1817-03-04 | James Monroe | 58 |
ローカルセカンダリインデックスはどのように作成・使用したらよいですか?
先ほど述べたように、DynamoDBのテーブル作成時にローカルセカンダリインデックスを作成しなければなりません。AWS Management Consoleから作成する手順は次のとおりです。
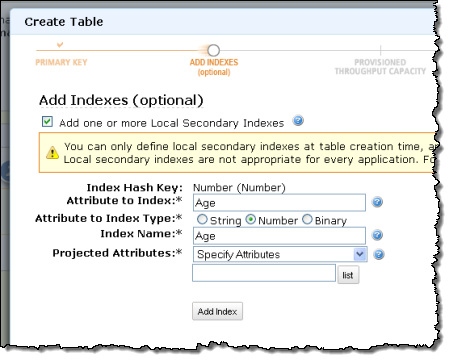
DynamoDBの既存のQuery APIはローカルセカンダリインデックスをサポートしています。APIコールはテーブル、インデックス名、返して欲しい属性、適用したい任意のクエリ条件を指定する必要があります。 Java, PHP, .NET / C# のサンプルも用意しております。
コストとプロビジョンドスループット
DynamoDBのコスト構造におけるローカルセカンダリインデックスの意味についてお話しましょう。
セカンダリインデックスを作成することで、DynamoDBの処理量が多くなります。ローカルセカンダリインデックスを持つテーブル内の項目を追加、削除、置換する場合、関連するインデックスを更新するために、余計に書き込み容量ユニットを使います。
1つ以上のローカルセカンダリインデックスを持つテーブルを照会する場合、次の2つの異なるケースを考慮する必要があります。
インデックスキーと投影された属性を使うクエリの場合、DynamoDBはテーブルからではなく、インデックスから読み取られ、それに応じた読み取り容量ユニットの数が計算されます。これにより、テーブルよりインデックス内の属性の方が少ない場合、コストの削減につながります。
投影されていない属性を読み取るインデックスクエリの場合、DynamoDBはテーブルとインデックスを読み取る必要があります。これにより追加の容量ユニットを消費することになります。
今すぐはじめましょう!
ローカルセカンダリインデックスは本日より、米国東部(北バージニア)、米国西部(オレゴンおよび北カリフォルニア)、南米(サンパウロ)、ヨーロッパ(アイルランド)、アジアパシフィック(東京、シンガポール、シドニー)リージョンでご利用いただけます。今すぐお試しください!