Amazon DynamoDBを使っているならば、すでにAWS Data Pipelineを使って、Amazon S3に定期的にバックアップを作成したり、S3からDynamoDBにデータをロードしたりしているかもしれません。
本日、DynamoDBのテーブル内にあるデータを、ご希望のリージョンの他のテーブルに定期的にコピーを行える新機能をリリースいたしました。 コードのエラーがオリジナルのテーブルを壊してしまうといった場合のためのディザスタリカバリ(DR)や、マルチリージョンアプリケーションをサポートするために、DynamoDBのデータをリージョンを超えて連携させるために、このコピーを使うことができます。
AWS Data Pipelineを通してアクセスできる新しいテンプレートを使って、この機能にアクセスすることができます。
コピーするためには、テンプレートを選択し、パラメータを設定します。
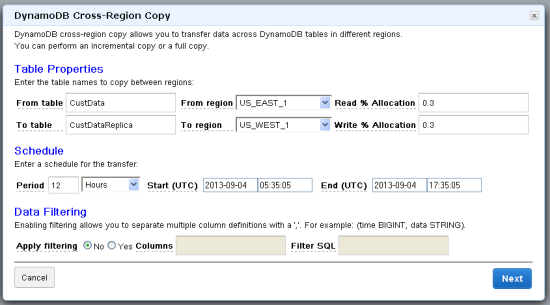
コピー元とコピー先のリージョン、テーブル名を入力します。Read および Write % Allocationは、コピーに割り当てるテーブルの総キャパシティユニットの割合です。さらに、コピーの頻度、最初のコピーの開始時間、必要に応じて、終了時間を設定します。
Data Filteringオプションを使うと、次の4つの異なるコピー操作のうちのいずれかを選択することができます。
Full Table Copy - Data Filteing パラメータに何も設定しない場合、全てのテーブル(全てのアイテムと全ての属性)がパイプラインが実行される度にコピーされます。
Incremental Copy - テーブルの各アイテムがタイムスタンプ属性を持っている場合、それをタイムスタンプ値として、Filter SQLフィールドに設定することができます。この設定ではコピー先のテーブル内のいかなるアイテムも削除することがないことに注意してください。もし削除したい場合は、物理削除の代わりに、(論理削除フラグをアイテムに持たせるなどして、)論理削除を実装することで対応することが可能です。
Selected Attribute Copy - 各アイテムの属性の一部だけをコピーしたい場合、Columnsフィールドに希望の属性を指定することができます。
Incremental Selected Attribute Copy - Incremental CopyとSelected Attribute Copyの操作を組み合わせて、各アイテムの属性の一部をインクリメンタルにコピーすることができます。
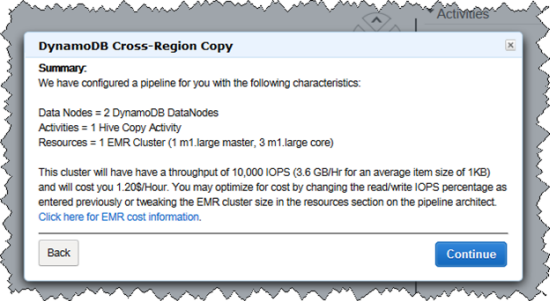
フォームを入力し終えると、コピーがどのように行われるのかをまとめた確認ウィンドウが表示されます。 Data Pipelineは、間に何も挟むことなく、直接コピー元のDynamoDBテーブルからコピー先のDynamoDBテーブルにデータを並列コピーするために、Amazon Elastic Map Reduce (EMR)を使用します。
DynamoDBテーブル間をデータコピーする機能を使う際には、通常のAWSのデータ転送料が適用されます。
AWS Data Pipelineは現在、米国東部(北バージニア)リージョンで利用可能で、そこから起動する必要があることに注意してください。 それでも、パブリックなAWSリージョンのいずれに配置されたテーブルでもデータをコピーすることができます。
いつものように、この機能は本日よりご利用いただけます!