このブログをよくご覧いただいている方は、Amazon Kinesisが、大規模なスケールでストリーミングデータをリアルタイムに処理する、完全マネージド型のサービスであることはすでにご存知でしょう。
先月、Kinesis Storm Spoutを紹介したときブログで書いたとおり、Kinesisは完全なエンドツーエンドのストリーミングデータアプリケーションの1構成要素に過ぎません。 このようなアプリケーションを構築するためには、ストリーミングデータの負荷分散や分散サービスの調整を行うためにKinesis Client Libraryを使ったり、他のデータストレージと連携し、サービスを処理するために、Kinesis Connector Libraryを使ったりする必要があります。
Kinesisの新しい EMR Connector
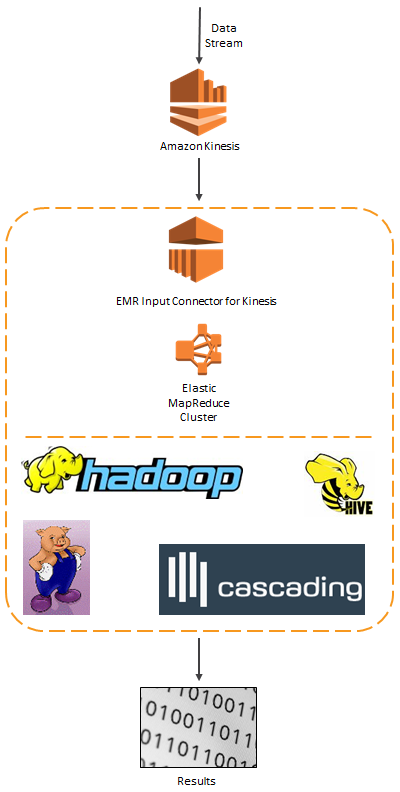
本日、Kinesisに新しくElastic MapReduce Connectorを追加いたしました。このコネクタを使えば、Hive、 Pig、 Cascading、Hadoop Streamingといった使い慣れたHadoopのツールを使って、ストリーミングデータを分析することができます。 KinesisとAmazon Elastic MapReduceを組み合わせてストリーミングデータアプリケーションの分析部分を構築すれば、両方のサービスの完全マネージドな特性からベネフィットを得ることができます。世界規模のリアルタイム処理を行うのに必要とされるインフラストラクチャーを構築し、デプロイし、管理することについて頭を悩ます必要がなくなります。このコネクターはElastic MapReduce AMIの3.0.4を利用可能です。
上記の部品全てを組み合わせると次のようになります。:
興味深いユースケース
この強力なサービスのペアを使ってなにができるでしょうか?ここでは使いはじめるためのいくつかのアイデアを紹介いたします。:
ITサイドでは、ログファイルを解析し、オペレーショナル・インテリジェンスを生成することができます。ウェブのログをKinesisに流し込み、数分毎にそれを分析し、地域毎、ページ毎に上位10件のエラーリストを生成するといった具合です。
ビジネスサイドでは、KinesisストリームをS3、DynamoDBのテーブル、およびHDFSに保存されたデータと結合することで、総合的なデータのワークフローを駆動することができます。例えば、Kinesisからのクリックストリームデータと、DynamoDBのテーブルに保存された広告キャンペーン情報を結合するクエリを書くことで、特定のウェブサイトに表示される最も効率的な広告カテゴリを特定することができます。
また、データをさらに分析するためにAmazon DyanamoDB、Amazon S3、Amazon Redshiftなどに保存する前に、入ってくるデータをフィルタリングしたり前処理したりするためにElastic MapReduceを使うこともできます。 特定のレコードタイプを除外したり、事前の計算を実行したり、複数レコードを集約したりといった具合です。
最後に、Kinesis ストリームを通して流れているデータにアドホックにクエリを実行することもできます。 コードに埋め込む前に、クエリーを作成しテストすることができます。 高速でインタラクティブな分析クエリを実行するために、定期的にKinesiからHDFSにドラフトをロードし、ローカルのImparaテーブルとして利用することもできます。
クエリーの実行には、2つの異なるオプションがあります。:
まず、インクリメンタルクエリーを実行することができます。この場合、コネクターはシャード毎にレコードの最初と終わりを追跡し、各バッチで新しく利用可能になったレコードのみを返します。チェックポイント情報はAmazon DynamoDBに保存されます。ダウンストリーム処理を単純化するために、固有のイテレーションナンバーが各バッチに割り当てられます。
もしくは、チェックポイントの動作を無効にし、ストリーム全体を紹介することもできます。これは、ストリームの中に存在する全てのデータにアクセスすることができます。このクエリーは過去24時間(Kinesis内でのデータの持続時間)にスライディングウィンドウを提供します。
ストリームをHive内のテーブルにマッピングする
Kinesisを介して届くデータの処理にHiveを使っている場合、テーブル定義は次のように終了することによって、Kinesisストリームを参照することができます。:
STORED BY'com.amazon.emr.kinesis.hive.KinesisStorageHandler'
TBLPROPERTIES("kinesis.stream.name"="AccessLogStream");複数のストリーム用にHiveテーブルを作ることができます。それから、通常の方法でそれらを結合することができます。チェックポイントが有効担っている場合は、これらのクエリーは両方のテーブルからイテレーションナンバーと論理名に対応するデータを処理します。
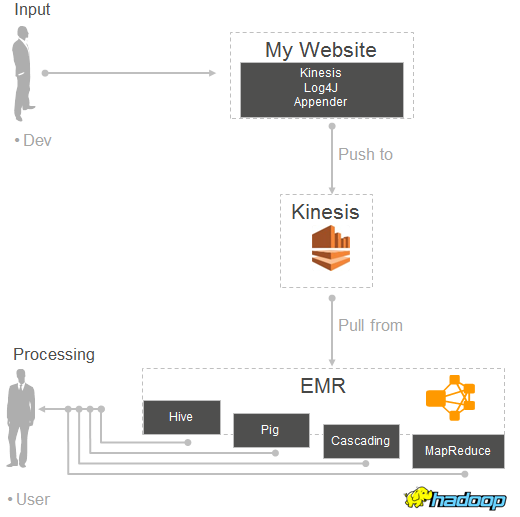
Kinesis Log4J Appender
大量のログ形式のデータをKinesisにプッシュすることに興味がある場合、Kinesis Log4J Appender (jarをダウンロード)を見てみることをオススメします。 Log4J Appenderを使えば、簡単に、継続的にログを直接Kinesisストリームにプッシュすることができます。次のような処理モデルを実装するために、このブログ記事に書かれている新しいコネクターと一緒にこれを使うことができます。
はじめよう
すでにElastic MapReduceおよびHadoopに慣れている場合、新しく用意したStreaming Data Analysis Tutorialsをご覧ください。 層でない場合は、Kinesis Getting Started GuideとElastic MapReduce documentationの中のWord Count exampleをまずはご覧ください。
この機能についてさらに詳しい情報については、Elastic MapReduce documentationのAnalyze Real-Time Data from Kinesis Streamsの章をご覧ください。 また、Elastic MapReduce FAQも更新されており、役に立つ情報が見つけられるはずです。
-- Jeff;
この記事はAWSシニアエバンジェリスト Jeff BarrのAmazon Web Services Blogの記事、 Process Streaming Data with Kinesis and Elastic MapReduceを 堀内康弘 (Facebook, Twitter)が翻訳したものです。